
Cluster
The Cluster task in Gaio DataOS aplica algoritmos de agrupamiento para agrupar registros con características similares. Es ideal para casos de uso como segmentación de clientes, reconocimiento de patrones y toma de decisiones basada en datos a partir de perfiles conductuales o estructurales. Gaio utiliza la técnica K-Means para identificar grupos y los cálculos de análisis se realizan en H2O, cuya documentación puede consultarse aquí.
Cómo usar la tarea Cluster
1. Abrir la tarea Cluster
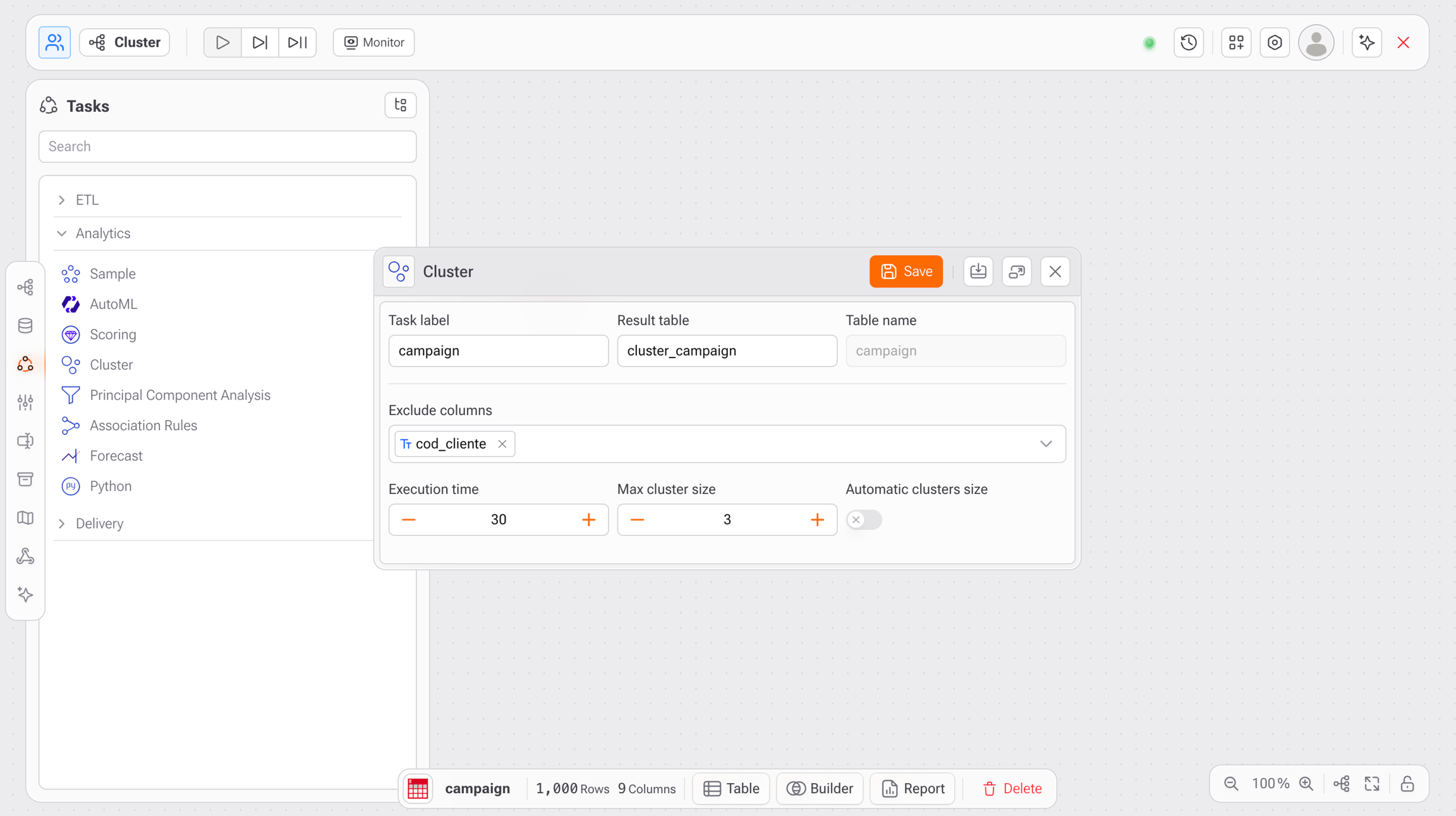
En el Studio, ve al panel Tareas. En la sección Analytics, selecciona Cluster.
2. Configurar la tarea
Etiqueta de la tarea: (opcional) Nombre para identificar este paso en tu flujo.
Tabla de resultado: Tabla de salida que contendrá los resultados del agrupamiento. Ejemplo:
cluster_campaign.Nombre de la tabla: Se completa automáticamente con la tabla seleccionada (ej.:
new_sales).
3. Excluir columnas (opcional)
En el campo Excluir columnas, agrega las columnas que no deben considerarse en el proceso de agrupamiento, como identificadores únicos (ej.: cod_cliente).
Esto ayuda a evitar sesgos o ruido en el algoritmo.
4. Ajustar configuración de ejecución
Tiempo de ejecución Define el tiempo máximo de ejecución del algoritmo de agrupamiento (en segundos). Recomendado: entre 20 y 60 segundos, dependiendo del tamaño y la complejidad del conjunto de datos.
Cantidad máxima de clusters Define el número máximo de clusters que el algoritmo puede crear. Ejemplo: si se establece en 3, la salida contendrá hasta 3 grupos distintos.
Cantidad automática de clusters Cuando está habilitado, Gaio determinará automáticamente el número ideal de clusters en función de la variabilidad de los datos. Cuando está deshabilitado, seguirá estrictamente el límite manual establecido en Cantidad máxima de clusters.
5. Guardar y ejecutar
Haz clic en Guardar para confirmar la configuración de la tarea. Ejecuta el flujo — la tabla de salida contendrá los datos agrupados.
Resultado
La tabla resultante incluirá:
Todas las columnas originales (excepto las configuradas para ser ignoradas).
Una nueva columna indicando el ID de cluster asignado a cada fila.
Buenas prácticas
Utiliza tareas como Sample o Análisis de Componentes Principales (PCA) previamente para reducir la dimensionalidad y mejorar el rendimiento.
Elimina columnas irrelevantes o con alta cardinalidad que puedan distorsionar los resultados del agrupamiento.
Aprovecha el clustering para personalizar campañas, identificar perfiles de clientes, detectar anomalías o apoyar estrategias de retención.
Última actualización