
AutoML
O Gaio utiliza a tecnologia H2O AutoML (Automatic Machine Learning) para criar modelos preditivos de forma automatizada. Isso significa que o Gaio operacionaliza todo o processo: conexão com os dados, processamento, envio das diretrizes de treino e modelagem para o H2O AutoML, recuperação dos resultados da execução e entrega desses resultados em uma interface amigável ao usuário. Todo esse fluxo pode ser totalmente automatizado dentro do Gaio.
Como usar o AutoML
Como usar o AutoML
1. Acessar a task AutoML
No menu lateral esquerdo, vá até Analytics e selecione a tarefa AutoML.
2. Configurar o modelo
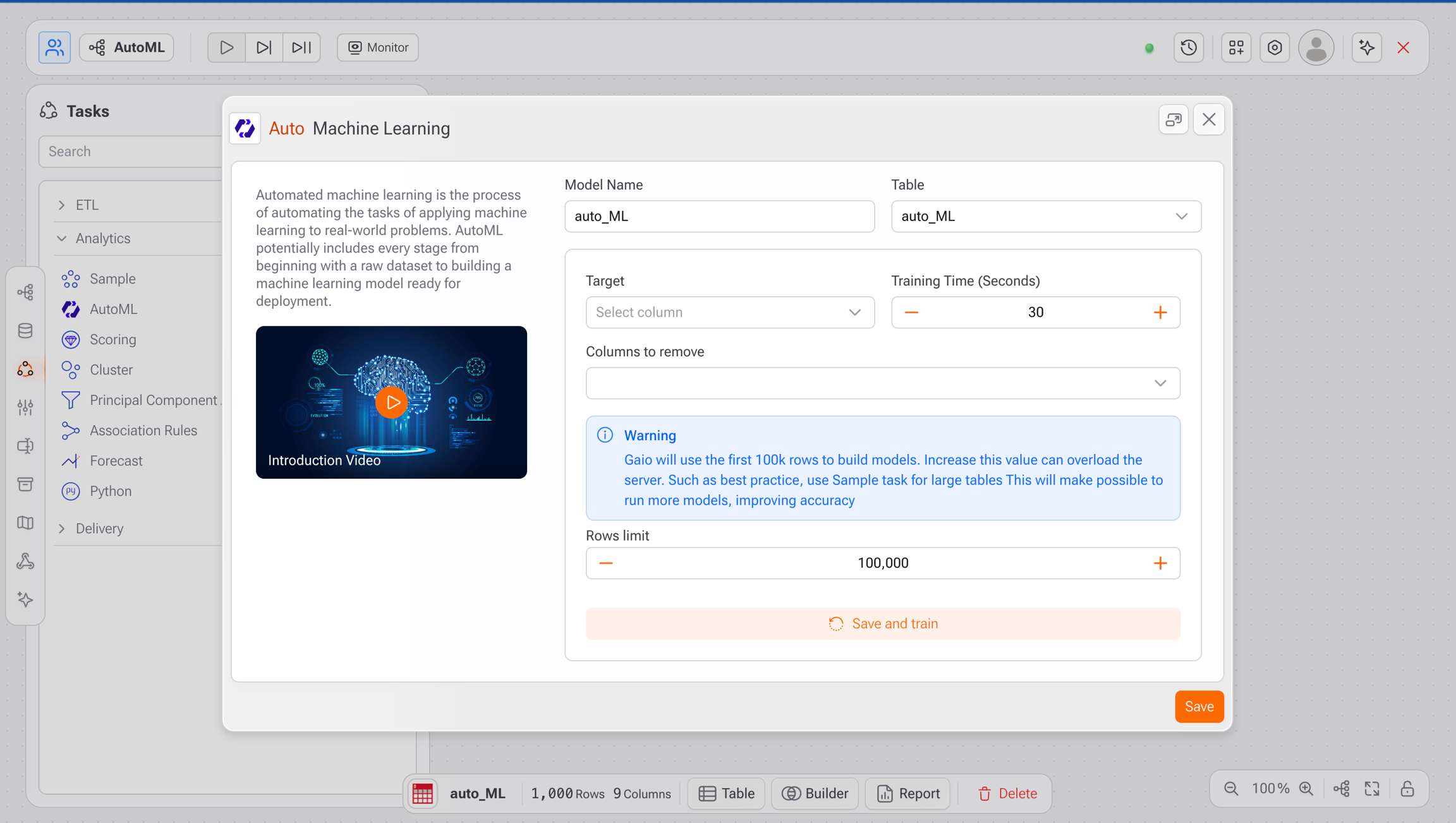
Na tela de configuração:
Nome do Modelo (opcional): Informe um nome para o modelo (ex.:
auto_ML).Tabela: Selecione a tabela que será usada como fonte de dados.
Alvo: Escolha a variável que deseja prever (ex.:
status).Colunas para remover: Informe colunas que devem ser excluídas do treinamento (ex.: IDs).
Tempo de treinamento (Segundos): Tempo estimado que o sistema utilizará para treinar os modelos.
Limite de linhas: Por padrão, o Gaio utiliza até 100.000 linhas para o treinamento. Esse valor pode ser ajustado, porém valores mais altos podem sobrecarregar o servidor.
O processo de modelagem costuma ser intensivo em memória e processamento. Por isso, é fundamental ter atenção ao volume de dados utilizado. Uma boa estratégia é utilizar uma amostra representativa do dataset, o que geralmente mantém a qualidade do modelo, permite criar mais modelos em menos tempo e evita sobrecarga do servidor. Para grandes volumes de dados, utilize a Amostragem antes do AutoML para reduzir o volume e otimizar a performance. Embora seja possível alterar o limite padrão de 100 mil linhas, isso só é recomendado em cenários onde o servidor possui grande capacidade.
Clique em Salvar e Treinar para iniciar o processo.
3. Acompanhar o progresso
Durante o treinamento, a interface exibe duas barras de progresso:
Preparation: Etapa de preparação e pré-processamento dos dados
Training: Construção e teste dos modelos
4. Técnicas utilizadas
Diversas técnicas são aplicadas no processo de modelagem automática. Abaixo estão algumas delas, com referência à documentação oficial do H2O:
GLM (Generalized Linear Model)
XGBoost: Combinação de múltiplas árvores de decisão criadas em paralelo
GBM (Gradient Boosting Machine)
DeepLearning: Uso de Redes Neurais
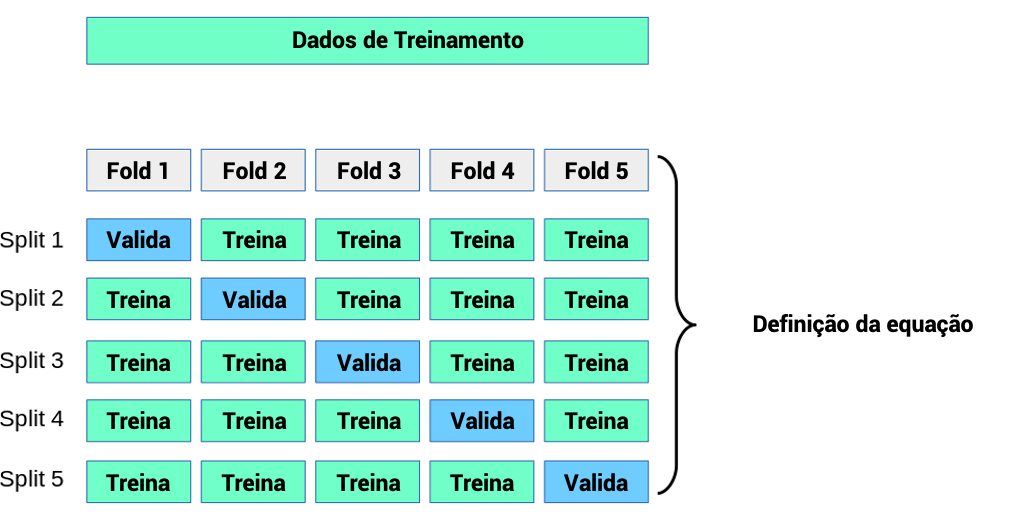
Critérios de treino e validação são aplicados automaticamente. O Gaio utiliza Cross-Validation para avaliar a assertividade dos modelos.
É utilizado 5-Fold Cross-Validation, que gera 5 amostras aleatórias do mesmo tamanho para treinar diversos modelos.
O critério principal para priorização do modelo é a Accuracy.
Variáveis de resposta
Variáveis Categóricas (texto) e Numéricas são aceitas como variáveis alvo.
Quando a variável de resposta é numérica, o Gaio entende que o objetivo é prever um valor numérico, e não a probabilidade de ocorrência de um evento.
Se a variável de resposta for Cancelamento de Serviço com valores 0 ou 1, será necessário transformá-los em algo como R0 ou R1. Isso porque, nesse caso, o objetivo é calcular a probabilidade do cliente cancelar (1) ou não cancelar (0).
Caso contrário, sendo numérica, o Gaio interpretaria que o objetivo é prever um número absoluto, como o valor de uma compra. Técnicas e resultados distintos são aplicados dependendo do tipo da variável de resposta.
5. Revisar os resultados
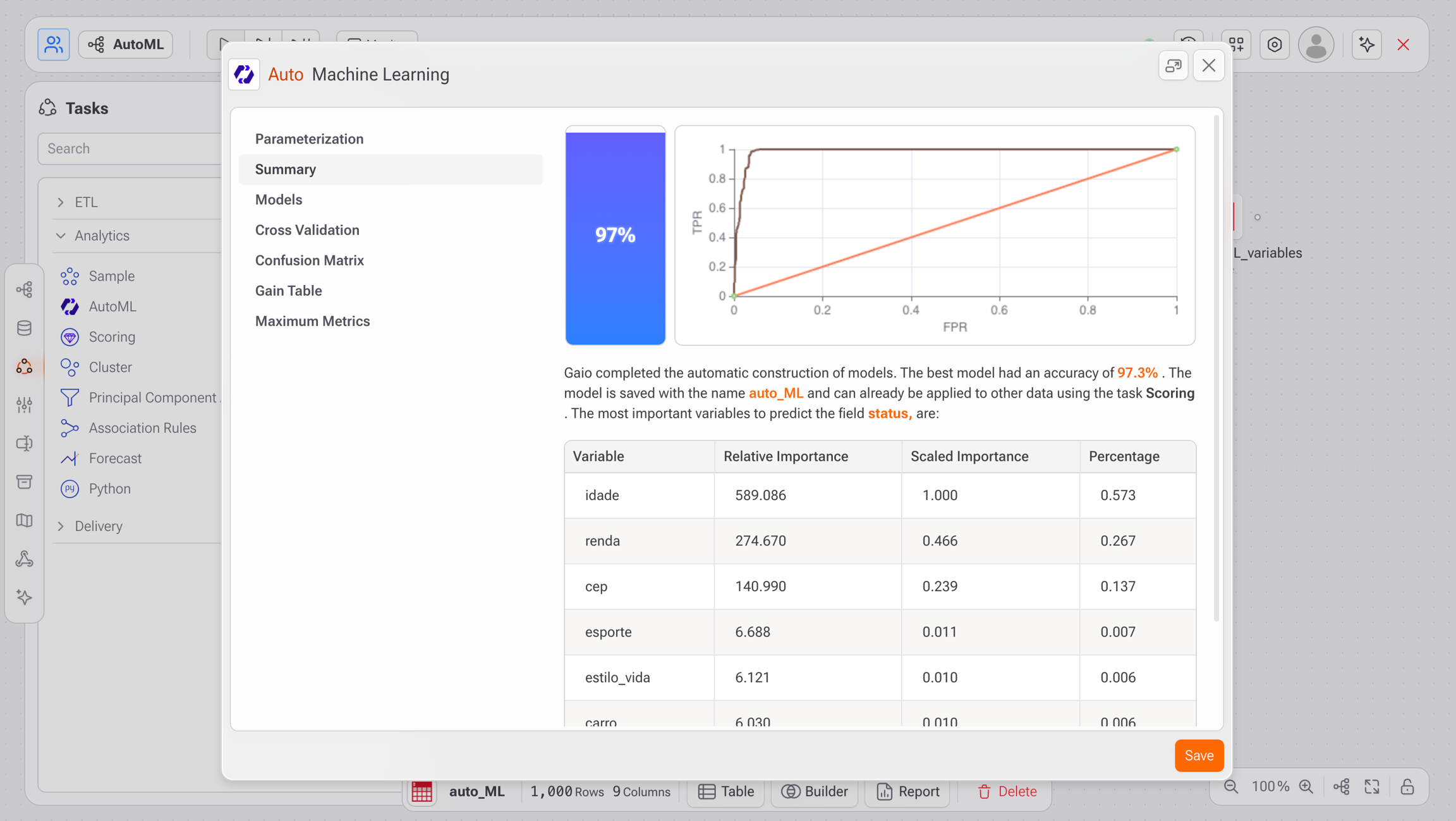
Após a conclusão, o sistema exibirá um relatório completo contendo:
Summary: Resumo do processo automático de construção do modelo e avaliação geral da qualidade
Model Accuracy: Acurácia do melhor modelo gerado
ROC Curve: Representação visual da performance do modelo
Most Important Variables: Lista das variáveis mais importantes para a predição
Models: Lista de todos os modelos criados dentro do tempo definido, com estatísticas de qualidade
Tabelas de apoio
Cross Validation
Confusion Matrix
Gain Table
Maximum Metrics
6. Aplicar o modelo
O modelo treinado é salvo e pode ser reutilizado por meio da Scoring Task, permitindo aplicar previsões a novos conjuntos de dados.
Atualizado